
Dlaczego nie potrzebujesz TRIM na serwerach
- Rozmiary sektorów
- Wzmocnienie zapisu (wzmocnienie zapisu)
- Kopiuj podczas pisania
- Gdzie zdobyć czyste bloki?
- TRIM
- Zbieranie śmieci w tle (zbieranie śmieci w tle)
- TRIM i rzeczywistość
- Wniosek
Po pierwsze, powinieneś zrozumieć, jak działa SSD, co to jest zbieranie śmieci, jak działa TRIM, a co najważniejsze, dlaczego nie jest potrzebny w serwerach.
Dysk SSD różni się od dysku twardego nie tylko ograniczonymi zasobami komórkowymi. Istnieje wiele innych cech architektonicznych.
Rozmiary sektorów
Standardowy rozmiar sektora dla większości urządzeń blokowych (dyski twarde i systemy pamięci masowej) wynosi 512 bajtów (w przypadku niektórych dysków SAS / SCSI możliwe jest 520/528 bajtów w celu dodatkowego monitorowania integralności danych). Ostatnie kilka branż próbuje przejść do sektorów o wielkości 4096 bajtów (4 KiB), tzw Format zaawansowany. Proces postępuje powoli, na razie wszystko zatrzymało się na 512e , tj. dyski z sektorami 4K wewnątrz, ale z emulacjami 512 bajtów dla hosta. Na dyskach 512e mogą pojawić się problemy z wydajnością: jeśli to konieczne, zapisz blok danych o rozmiarze mniejszym niż 4 KiB do kontrolera dysku, musisz odczytać sektor, zmienić w nim dane, a następnie odpisać. W przypadku dysków SSD sytuacja z pisaniem małych bloków jest jeszcze trudniejsza:
Kontroler SSD jest nadal zmuszony udawać urządzenie blokowe z sektorem 512 bajtów. Ale w środku wszystko jest bardziej skomplikowane: komórki są połączone w strony wielkości, z reguły 4-8 KiB, tj. jest to minimum dostępne do odczytu lub zapisu głośności. Po prostu niemożliwe jest zapisanie danych do komórki / strony, w tym celu najpierw należy wykonać operację kasowania, a można tylko wymazać cały blok składający się z kilkudziesięciu (na przykład 64 lub 128, w zależności od architektury SSD), tj. minimalnym blokiem dostępnym do usunięcia może być rozmiar, na przykład 512 KiB.
Wzmocnienie zapisu (wzmocnienie zapisu)
Termin ten odnosi się do relacji między ilością danych, które są rzeczywiście zapisane w pamięci flash, a ilością zapisywaną przez hosta. Załóżmy, że mamy blok 512 KiB z danymi i musimy zmienić mały fragment. Aby zmodyfikować sektor do 512 bajtów, kontroler SSD musi wykonać kilka operacji (sytuacja przypomina karę zapisu dla RAID-5/6):
- odczytaj cały blok do bufora
- zmodyfikuj zawartość bufora
- wytrzyj cały blok
- napisz nową zawartość bufora
To znaczy dla wielkości transakcji 512 bajtów na dysku SSD o rozmiarze bloku 512 KiB uzyskujemy wzmocnienie zapisu = 1024 razy. Nie jest to najlepszy efekt na a) wydajność i b) zasób, który wciąż wynosi kilka tysięcy cykli przepisywania dla SSD MLC .
Kopiuj podczas pisania
Problem wzmocnienia zapisu ma proste rozwiązanie: musisz spróbować zapisać dane w już wcześniej skasowanych blokach. Przydaje się klasyczny algorytm kopiowania przy zapisie, którego warianty służą do optymalizacji zapisu do RAID-DP w Netapp lub ZFS (tylko warstwa powyżej znajduje się na poziomie systemu plików).
Istotą algorytmu kopiowania przy zapisie jest pisanie do „dochodowych” obszarów nośnika, tj. w przypadku SSD - na czystych (wymazanych) blokach. W poniższym przykładzie zawartość strony „B” została zmodyfikowana. Zamiast czytać / kasować / zapisywać cały duży blok, wszystko, co musisz zrobić, to odczytać zawartość strony, zmodyfikować ją i zapisać w innym miejscu. Jednocześnie konieczna jest zmiana wskaźnika, tak aby ten sam LBA wskazywał na nową fizyczną lokalizację danych.
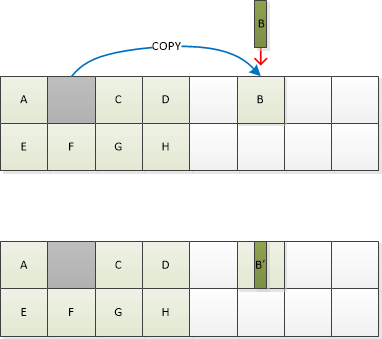
Jako dodatkowy sposób radzenia sobie ze wzmocnieniem zapisu większość nowoczesnych kontrolerów SSD wykorzystuje kompresję danych.
Gdzie zdobyć czyste bloki?
Na nowym dysku SSD wszystkie bloki są czyste i gotowe do zapisu. Następnie istnieje obszar kopii zapasowych, który jest w rzeczywistości zawsze używany, ponieważ oprócz optymalizacji zapisu konieczne jest zapewnienie równomiernego zużycia komórek SSD.
TRIM
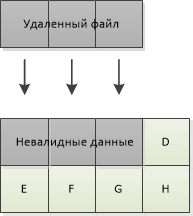
Co jeśli po ciągłym zapisywaniu czystych bloków już tam nie ma? W każdym razie możesz dowiedzieć się, gdzie na dysku SSD znajdują się dane użytkownika i gdzie znajdują się nieprawidłowe dane, pozostające po usunięciu plików. Właściwie to właśnie robi TRIM. SSD, jak każde inne urządzenie blokowe, nie wie nic o tym, jakie dane są na nim przechowywane. System operacyjny może współdziałać zarówno z warstwą systemu plików, jak iz urządzeniem blokowym, tj. po usunięciu pliku system operacyjny przenosi się na dysk SSD wraz z komendą TRIM (lub UNMAP for SCSI) listę LBA, dla których usunięto usunięte dane. Dysk SSD pobiera dostępne bloki z nieprawidłowymi danymi, a te bloki mogą być dalej wykorzystywane do nagrywania.
Zbieranie śmieci w tle (zbieranie śmieci w tle)
Drugim oczywistym sposobem wykrywania nieprawidłowych danych jest powtarzanie żądań zapisu z hosta dla tego samego LBA. Dla hosta wygląda na to, że nadpisuje się te same sektory, ale dysk SSD próbuje cały czas zapisywać do różnych bloków. Na powyższej ilustracji operacji kopiowania podczas zapisu rzeczywiste dane znajdują się na nowej stronie „B”, po czym nieprawidłowe dane pozostają na stronie początkowej.
Regiony z nieprawidłowymi danymi mogą być bardzo pofragmentowane, tj. zawierają komórki z niezbędnymi danymi. Ostatnim krokiem pozostaje defragmentacja tych obszarów, otrzymanie zestawu całych wolnych bloków i ich wymazanie.

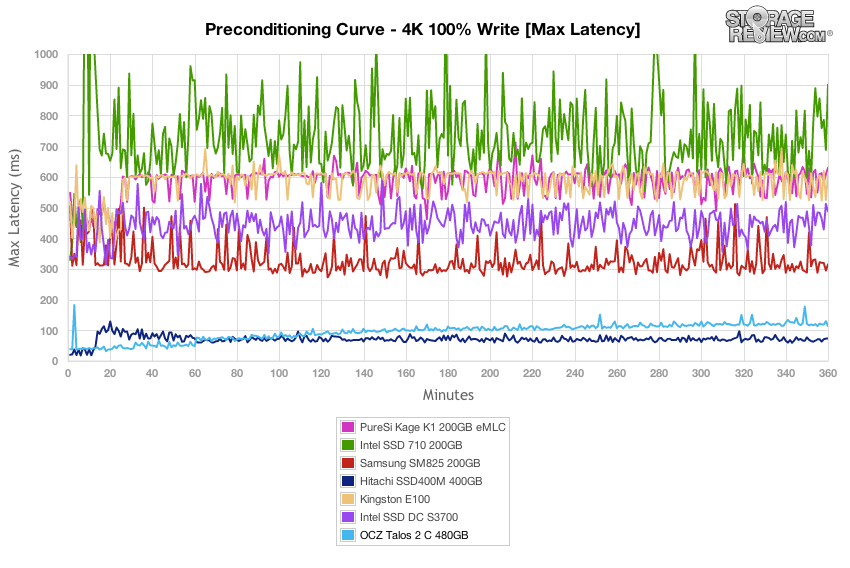
Właściwie za to wszystko odpowiedzialne jest zbieranie śmieci. „Prawidłowe” dyski SSD o dużej intensywności zapisu mają wystarczającą rezerwę (obszar zapasowy) jako „przestrzeń do manewru” i wydajny kontroler z wystarczającą pamięcią podręczną (oczywiście chronioną przez kondensatory) do metadanych hosta i buforowania odczytu / zapisu. Jeśli kontroler nie ma czasu na szybkie przygotowanie miejsca do szybkiego nagrywania, to nieuchronnie wpłynie to na wydajność, będzie okresowy wzrost opóźnień kilka razy w stosunku do średniej wartości, jak na tym zdjęciu z www.storagereview.com :
TRIM i rzeczywistość
Aby TRIM działał, oprócz spełnienia różnych warunków (wsparcie z systemu operacyjnego i systemu plików), konieczne jest radzenie sobie z innymi warstwami abstrakcji, na przykład RAID. Teoretycznie możliwe jest ponowne obliczenie adresów pochodzących z TRIM do kontrolera z hosta i rozproszenie ich na poszczególnych dyskach, ale nikt ( Lsi nie Adaptec firmy PMC ) nie spieszy się z wdrożeniem. Powód jest prosty - poza systemami domowymi lub stacjami roboczymi tak prosta rzecz, jak usunięcie pliku jest niezwykle rzadka. W serwerach z reguły istnieją zupełnie inne obciążenia, na które TRIM nie może mieć żadnego związku:
- Wirtualizacja Dysk fizyczny lub wolumin kontrolera RAID zawiera jeden system plików (VMFS / NTFS / XFS), a na nim jest dysk wirtualny jako plik (który nie jest usuwany w dowolnym miejscu i nawet nie zmienia rozmiaru, jeśli dysk nie jest cienki) oraz wewnątrz wirtualnego dysk - inny FS. Jak, od kogo i komu przekazywać TRIM w takiej sytuacji, jest zupełnie niezrozumiałe.
- Zapewnienie dostępu blokowego . To dodaje kilka poziomów abstrakcji. Volume-> Section (lub FS + file) -> Target-> File System
- Dostęp do plików . W organizacjach z reguły nikt regularnie nie usuwa dużej liczby plików. Taki scenariusz występuje tylko podczas przechowywania tymczasowej zawartości multimedialnej, na przykład podczas renderowania lub transkodowania wideo, a dysk SSD nie jest tutaj absolutnie potrzebny. Serwer plików jest zwykle używany do długoterminowego przechowywania informacji.
- Bazy danych . Plik, który ponownie nie jest usuwany, ale tylko modyfikowany i rośnie.
Wniosek
Używaj zgodnych dysków SSD ze sterownikiem, wybierz je na podstawie oczekiwanego obciążenia nagrywania i nie martw się o TRIM.
Gdzie zdobyć czyste bloki?