
Управление поисковыми системами для лучшей индексации
- Сканирование и индексация в нескольких словах Управляйте процессами сканирования и индексации на...
- Как работает индексирование?
- Как повлиять на сканирование и индексирование
- Методы контроля сканирования и индексации
- Окончательный чит на Crawling and Indexing
- Директивы роботов
- Канонический URL
- Атрибут Hreflang
- Атрибуты пагинации
- Мобильный атрибут
- Часто задаваемые вопросы о сканировании и индексировании
- Исследуйте как поисковые системы: поставьте себя на их место
- Другие ситуации, когда функция Explorer, такая как Google, оказывается удобной
- 1. Часто ли Google ищет мой сайт?
- 2. Могу ли я замедлить сканеры, когда они исследуют мой сайт?
- 4. Что означает индексация сайта?
- 5. Может ли мой сайт быть проиндексирован поисковыми системами?
- 6. Часто ли Google индексирует мой сайт?
- 7. Сколько времени понадобится Google, чтобы проиндексировать мой сайт?
Сканирование и индексация в нескольких словах
Управляйте процессами сканирования и индексации на своем сайте, сообщая свои предпочтения поисковым системам.
Вы поможете им понять, на каких частях вашего сайта они должны сосредоточиться, а какие игнорировать. Есть много способов пойти, так какой метод применять, когда?
В этой статье мы увидим, когда использовать каждый метод, выделяя преимущества и недостатки.
Поисковые системы каждый день охватывают миллиарды страниц, но они не индексируют так много и отображают в своих результатах еще меньше. Ваша цель - чтобы ваши страницы были среди них. На данный момент, как вы можете повлиять на этот процесс и улучшить SEO?
Чтобы ответить на этот вопрос, сначала нужно посмотреть, как работают сканирование и индексирование. Затем мы увидим возможные методы контроля над процессом.
Как работает сканирование?
Сканеры , иногда называемые «пауками», отвечают за поиск и изучение как можно большего количества URL-адресов. Они проверяют, что контент на самом деле там. Эти URL-адреса могут быть новыми, так как сканеры уже знают. Новые URL-адреса обнаруживаются путем изучения ранее известных страниц. После фазы исследования результаты отправляются для индексации. На английском языке страницы, которые могут сканировать поисковые системы, называются сканируемыми .
Как работает индексирование?
Индексаторы , или «индексирующие роботы» на французском языке, получают содержимое URL-адресов сканеров. Затем индексаторы пытаются разобраться в этом содержании, анализируя его (включая ссылки, если таковые имеются). Индексатор обрабатывает канонические URL-адреса и определяет полномочия каждого URL-адреса. Индексирование также определяет, должна ли страница быть проиндексирована. Страницы, которые поисковые системы могут индексировать, называются индексируемыми , английский термин взят на французском языке.
Индексаторы также отображают страницы и запускают JavaScript. Если ссылки найдены, они возвращаются сканеру.
Как повлиять на сканирование и индексирование
Вы можете контролировать сканирование и индексирование, четко указав свои предпочтения для поисковых систем. Таким образом, вы помогаете им понять, какие разделы ваших сайтов наиболее важны для вас.
В этой главе мы увидим все методы и какие методы следует использовать в какое время. Мы также разработали диаграмму, чтобы проиллюстрировать, что каждый метод может и не может делать.
Давайте начнем с объяснения некоторых понятий:
- Навигация: возможность сканирования на английском языке; могут ли поисковые системы сканировать URL?
- Индексируемый: поощряется ли поисковая система индексировать URL?
- Предотвратить дублирование контента: предотвращает ли этот метод появление Проблемы с дублированием контента ?
- Консолидация сигналов: поощряются ли поисковые системы к релевантности вашей страницы и авторитет URL по содержанию URL и ссылкам?
Прежде всего, важно понять, что обход бюджета , Бюджет сканирования - это время, которое сканеры поисковых систем проведут на вашем сайте. Ваша цель состоит в том, чтобы они проводили это время разумно, и для этого вы можете дать им инструкции.
Методы контроля сканирования и индексации
robots.txt

файл robots.txt это база данных, которая предоставляет основные правила для сканеров. Мы называем эти правила руководящими принципами. Если вы хотите запретить сканерам исследовать определенные URL-адреса, robots.txt - лучший способ сделать это.
Если сканерам не разрешено сканировать URL-адрес и сохранять его содержимое, индексатор никогда не сможет сканировать его содержимое и ссылки. Это может позволить вам избежать дублирования контента, но это также означает, что рассматриваемый URL никогда не будет сохранен. Поисковые системы также не смогут объединять сигналы релевантности и авторитета, поскольку они не знают, что находится на этой странице. Эти сигналы будут потеряны.
Окончательный чит на Crawling and Indexing
Поиск, как управлять поисковыми системами, занимает вашу голову? Экономьте время с правильными методами!
Пример использования robots.txt
Раздел администратора сайта является хорошим примером того, где можно применить файл robots.txt и запретить доступ сканерам к нему. Предположим, что раздел администратора находится по этому адресу: https://www.example.com/admin/.
Запретите сканерам доступ к этому разделу с помощью следующей команды в вашем файле robots.txt:
Disallow / admin
Вы не можете редактировать свой файл robots.txt? Применить директива noindex по роботам в разделе / admin.
Важные заметки
Обратите внимание, что URL-адреса, запрещенные для сканеров, могут по-прежнему появляться в результатах поиска. Это происходит, когда URL-адреса доступны с других страниц или когда поисковые системы уже знают их, прежде чем запретить их с помощью robots.txt. Поисковые системы будут отображать сообщение, такое как это:
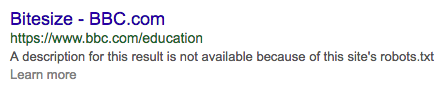
Файл robots.txt не может решить существующие проблемы с дублированным содержимым. Поисковые системы не забудут URL только потому, что не могут получить к нему доступ.
Добавление канонического URL-адреса или метатега роботов noindex к URL-адресу, заблокированному robots.txt, не приведет к его деиндексации. Поисковые системы никогда не узнают о вашем запросе деиндексации, потому что ваш файл robots.txt не позволяет им увидеть его.
Файл robots.txt является важным инструментом для оптимизации бюджета сканирования вашего сайта. Используя robots.txt, вы можете указать поисковым системам, какие части вашего сайта им не нужны и не должны быть изучены.
Что будет делать файл robots.txt:
- Запретить поисковым системам доступ к определенным частям вашего сайта, тем самым экономя бюджет сканирования.
- Запретить поисковым системам индексировать определенные части вашего сайта, если ни одна ссылка не ведет на него.
- Предотвратить проблемы с дублированным контентом.
Что файл robots.txt не собирается делать:
- Консолидация сигналов актуальности и авторитета.
- Удалить уже проиндексированный контент *.
* Хотя Google поддерживает директива noindex и фактически удалит содержимое, мы не рекомендуем использовать этот метод, потому что он официально не утвержден. Только Google поддерживает его, и его эффективность не гарантируется на 100%. Используйте только если вы не можете использовать правила робота или Канонический URL ,
Хотите узнать больше о robots.txt?
Взгляните на Robots.txt справочное руководство ,
Директивы роботов

Директивы роботов говорят поисковым системам, как индексировать страницы, оставляя страницы доступными для посетителей. Они часто используются, чтобы указывать движкам не индексировать определенные страницы. С точки зрения индексации, это более сильный сигнал, чем тот, который посылается по каноническому URL.
Реализация тега meta robots на некоторых страницах обычно осуществляется путем интеграции его непосредственно в источник. Для других типов документов, таких как PDF-файлы или изображения, используйте HTTP-заголовок X-robots-tag.
Пример использования директив роботов
Предположим, у вас есть десять целевых страниц для трафика Google AdWords. Вы скопировали содержимое других страниц, слегка изменив их. Эти страницы не должны быть проиндексированы, так как это приведет к дублированию контента. В этот момент вы интегрируете директиву robots с инструкцией noindex.
Важное примечание
Директивы роботов помогают вам предотвратить появление дублированного контента, но они не добавляют никакой ценности с точки зрения релевантности или авторитета URL.
В дополнение к указанию поисковым системам не индексировать страницу, оператор noindex тега meta robots также удерживает их от изучения. Вы экономите бюджет обхода.
Вопреки тому, что указано в его названии, директива nofollow robots не влияет на сканирование страницы с этим атрибутом. Однако, когда установлена директива атрибута robots nofollow, сканеры поисковых систем больше не будут использовать ссылки на этой странице для сканирования других страниц. Поэтому никакие полномочия не будут переданы этим другим страницам.
Что делают директивы роботов:
- Запретить поисковым системам индексировать части вашего сайта.
- Предотвращение повторяющихся проблем с содержимым
Что директивы роботов не делают:
- Запретить поисковым системам исследовать определенные части вашего сайта и сэкономить бюджет сканирования.
- Консолидация сигналов актуальности и авторитета.
Хотите узнать больше о правилах использования роботов?
Взгляните на окончательное руководство по мета теги роботов ,
Канонический URL

Канонический URL сообщает поисковым системам каноническую версию страницы, поощряя их индексировать эту конкретную версию. Канонический URL может ссылаться на себя или на другие страницы. Если вы хотите, чтобы посетители имели доступ к разным версиям одной и той же страницы, а также к тому, что поисковые системы рассматривают их как одну версию, вам нужен канонический URL. Когда одна страница ссылается на другую с использованием канонического URL-адреса, большая часть ее релевантности и авторитета передается целевому URL-адресу.
Пример использования канонического URL
Предположим, у вас есть сайт электронной коммерции с тремя категориями продуктов. Продукт доступен с трех разных URL. Все это хорошо для посетителей, но лучше для поисковых систем сканировать и индексировать один URL. Выберите одну категорию в качестве основной и канонизируйте две другие в соответствии с первой.
Важные заметки
Обязательно примените перенаправление 301 к URL-адресам, которые бесполезны для посетителей из-за канонической версии. Это позволяет передать всю их авторитетность и актуальность канонической версии. Это также поможет вам заставить другие сайты перенаправлять своих посетителей на каноническую версию.
Канонический URL - это скорее руководство, чем директива. Поисковые системы могут решить игнорировать это.
Применение канонического URL-адреса не сохранит бюджет сканирования, поскольку не мешает поисковым системам сканировать страницы. Это предотвращает отображение этих страниц в случае поискового запроса, поскольку они связаны с канонической версией URL.
Что делает канонический URL:
- Запретить поисковым системам индексировать части вашего сайта.
- Предотвратить проблемы с дублированным контентом.
- Консолидировать большинство сигналов актуальности и авторитета.
Что канонический URL не делает:
- Запретить поисковым системам исследовать определенные части вашего сайта и тем самым сэкономить бюджетные обходы.
Хотите узнать больше о канонических URL?
Взгляните на канонический справочник URL ,
Атрибут Hreflang

Атрибут rel = "alternate" hreflang = "x", или кратко атрибут hreflang, используется для связи поисковых систем с языком, используемым для вашего контента, и для какого географического региона он предназначен. Если вы ориентируетесь на несколько регионов с одним или похожим контентом, атрибут hreflang для вас. Это позволяет вам быть на каждом рынке с одинаковым контентом и избегать дублирования контента.
Тем не менее, это не предотвращает дублирование контента. Представление абсолютно одинакового контента в Соединенном Королевстве и Соединенных Штатах можно рассматривать как дублирующий контент. Помимо дублированного контента, вы должны убедиться, что ваш контент подходит для вашей аудитории. Убедитесь, что ваш контент кажется ему знакомым. Для этого рекомендуется внести некоторые изменения в тексты и изображения, чтобы сопоставить их с Соединенным Королевством или Соединенными Штатами.
Пример использования атрибута hreflang
Вы ориентируетесь на несколько английских рынков, используя поддомен для каждого рынка. Содержание одинаково для каждого субдомена:
- www.example.com для рынка США (США)
- ca.example.com для канадского рынка
- uk.example.com для рынка Великобритании
- au.example.com для австралийского рынка
Для каждого рынка вы хотите, чтобы на вас ссылались с одинаковым контентом и избегали дублирования контента. Это где hreflang приходит.
Что делает атрибут hreflang:
- Ориентируйте несколько разных аудиторий с одним контентом.
- Избегайте дублирования проблем с контентом.
Что не делает атрибут hreflang:
- Запретить поисковым системам исследовать определенные части вашего сайта и, таким образом, сэкономить бюджет сканирования.
- Запретить поисковым системам индексировать части вашего сайта.
- Консолидация сигналов актуальности и авторитета.
Хотите узнать больше об атрибуте hreflang?
Взгляните на полное руководство по атрибуту hreflang ,
Атрибуты пагинации

Атрибуты rel = "prev" и rel = "next" , или сокращенные атрибуты пагинации , используются для того, чтобы сообщать поисковым системам об отношениях внутри ряда страниц. Для серий похожих страниц, таких как страницы разбитых на страницы архивов блога или страницы для разных категорий продукта, они также разбиты на страницы, лучше использовать атрибут нумерации страниц. Поисковые системы поймут, что страницы очень похожи, что позволит избежать проблем с дублированием контента.
В большинстве случаев поисковые системы не будут ранжировать страницы, кроме первой страницы в серии.
Что делают атрибуты пагинации:
- Избегайте дублирования проблем с контентом.
- Консолидация сигналов актуальности и авторитета.
Какие атрибуты пагинации не будут делать:
- Запретить поисковым системам исследовать определенные части вашего сайта и тем самым сэкономить бюджетное сканирование.
- Запретить поисковым системам индексировать части вашего сайта.
Хотите узнать больше об атрибутах нумерации страниц?
Взгляните на полное руководство по нумерации страниц ,
Мобильный атрибут

Мобильный атрибут rel = "alternate" или, для краткости, мобильный атрибут , сообщает поисковым системам отношения между компьютерной и мобильной версиями сайта. Это помогает поисковым системам распознавать, какой сайт подходит для какого устройства, и позволяет избежать проблем с дублированием контента во время процесса.
Что делает мобильный атрибут:
- Избегайте дублирования проблем с контентом.
- Консолидация сигналов актуальности и авторитета.
Что мобильный атрибут не делает:
- Запретить поисковым системам исследовать определенные части вашего сайта и сэкономить бюджет сканирования.
- Запретить поисковым системам индексировать части вашего сайта.
Хотите узнать больше о мобильном атрибуте?
Взгляните на полное руководство по мобильному атрибуту ,

Если вы не можете быстро внести изменения в свой сайт, вы можете изменить управление настройками в консоли поиска Google и в Bing для веб-мастеров. Управление параметрами определяет, как поисковые системы взаимодействуют с URL-адресами, содержащими параметр. При этом вы можете указать Google и Bing не изучать и / или не индексировать определенные URL-адреса.
Чтобы изменить управление параметрами, вам нужны URL-адреса, идентифицируемые по формату. Управление параметрами следует использовать только в определенных случаях, например, для сортировки, фильтрации, перевода и сохранения данных.
Важное примечание
Имейте в виду, что настройка всего этого для Google и Bing не повлияет на то, как другие поисковые системы будут исследовать ваш сайт.
Что делает управление настройками:
- Запретить поисковым системам исследовать части вашего сайта, экономя бюджет сканирования.
- Запретить поисковым системам индексировать части вашего сайта.
- Избегайте дублирования проблем с контентом.
- Консолидация сигналов актуальности и авторитета.
Что управление настройками не делает:
- Позволяет настроить сканирование и индексацию для отдельных URL-адресов.
HTTP-аутентификация вынуждает пользователей или компьютеры подключаться для доступа к сайту или его части.
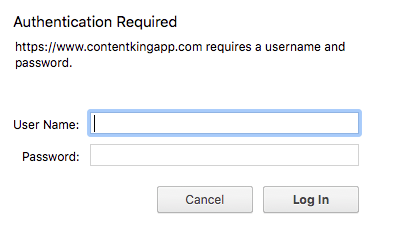
Без имени пользователя и пароля вы (или робот) не сможете выйти за пределы экрана входа и получить доступ ко всему. HTTP-аутентификация - отличный способ предотвратить попадание нежелательных посетителей, будь то люди или поисковые системы, например, в тестовую среду. Google рекомендует использовать HTTP-аутентификацию для предотвращения доступа сканеров к таким средам.
Если вы не хотите, чтобы частный или конфиденциальный контент появлялся в результатах поиска Google, самый простой и эффективный способ заблокировать частные URL-адреса - это сохранить их в защищенном паролем каталоге. перейти на сервер вашего сайта. Робот Googlebot и все остальные сканеры не могут получить доступ к содержимому в каталогах, защищенных паролем.
Что делает аутентификация HTTP:
- Запретить поисковым системам исследовать части вашего сайта, экономя бюджет сканирования.
- Запретить поисковым системам индексировать части вашего сайта.
- Избегайте дублирования проблем с контентом.
Что не делает аутентификация HTTP:
- Консолидация сигналов актуальности и авторитета.
Часто задаваемые вопросы о сканировании и индексировании
- Часто ли Google ищет мой сайт?
- Могу ли я замедлить сканеры, когда они исследуют мой сайт?
- Как я могу запретить поисковым системам сканировать сайт или страницу?
- Что означает индексация сайта?
- Может ли мой сайт быть проиндексирован поисковыми системами?
- Часто ли Google индексирует мой сайт?
- Сколько времени потребуется Google для индексации моего сайта?
- Как я могу запретить поисковым системам индексировать сайт или страницу?
Конечная шпаргалка по сканированию и индексированию
Быстро найти правильный метод для решения проблем сканирования и индексации!
Исследуйте как поисковые системы: поставьте себя на их место
Как сканеры поисковых систем видят ваши страницы и что ваши страницы приносят им? Поставьте себя на их место с помощью инструмента «Исследовать и просматривать».
Функция «Исследовать как Google» является наиболее известным примером. Он расположен в Google Search Console и позволяет вам создать URL на вашем сайте, и Google сообщит вам, что его сканеры видят на этом URL и что он отображает. Вы можете сделать это для компьютеров и мобильных версий. Ниже вы можете увидеть, как это выглядит:
Это очень полезно для проверки правильности ответа URL-адресов, а также для принудительной индексации URL-адреса («Запрос на индексирование»). В считанные секунды ваш URL сканируется и индексируется. Это не означает, что его содержимое немедленно обрабатывается и сохраняется, но позволяет ускорить процесс сканирования и индексации.
Другие ситуации, когда функция Explorer, такая как Google, оказывается удобной
Исследование как Google полезно не только для ускорения процесса сканирования и индексации отдельного URL-адреса, эта функция также позволяет:
- Ускорьте открытие новых разделов вашего сайта
Изучите URL, который ссылается на новые разделы, и нажмите «Индекс запроса» с опцией «Изучить этот URL и его прямые ссылки». - Получите аудит пользовательского опыта на мобильной версии:
Исследуйте URL как «Мобильный телефон: смартфон». - Убедитесь, что перенаправления -301 работают правильно.
Скопируйте URL и проверьте, что отвечает заголовок.
Примечания:
- Третий случай еще проще выполнить для URL-адресов, сгруппированных с помощью ContentKing.
- Google позволяет запрашивать индексацию 500 URL-адресов в месяц.
- Google позволяет вам индексировать только 10 URL-адресов в месяц, если вы запрашиваете также обход всех связанных URL-адресов.
- Bing предлагает аналогичный инструмент под названием " Исследуй как Бингбот ».
1. Часто ли Google ищет мой сайт?
Консоль поиска Google делится с вами своими данными сканирования. Чтобы получить к нему доступ:
- Войдите в консоль поиска Google и выберите сайт.
- Нажмите «Исследование»> «Статистика сканирования», и вы увидите, как часто Google выполняет поиск на вашем сайте.
Если вы немного знаете об этом, вы можете узнать, часто ли Google ищет ваш сайт, анализируя файлы журнала вашего сайта.
Интересно отметить, что Google определяет частоту посещений вашего сайта на основе обход бюджета размещены на вашем сайте.
2. Могу ли я замедлить сканеры, когда они исследуют мой сайт?
Хотя это не рекомендуется для Google и Bing, вы можете использовать директиву robots.txt Кроу задержки , Мы не рекомендуем это для Google и Bing, потому что сканеры достаточно умны, чтобы знать, когда ваш сайт не в лучшей форме, и они вернутся позже, чтобы проверить еще раз.
Есть несколько способов запретить поисковым системам исследовать определенные части вашего сайта или только несколько страниц:
- Robots.txt: может использоваться для предотвращения сканирования поисковыми системами сайта, определенных частей или отдельных страниц.
- Управление параметрами. Может использоваться для предотвращения сканирования URL-адресов, содержащего определенный параметр.
- HTTP-аутентификация: может использоваться для предотвращения просмотра всего сайта, его частей или отдельных страниц.
4. Что означает индексация сайта?
Индексирование - это процесс, с помощью которого оператор поисковой системы пытается прояснить смысл сайта, чтобы затем его можно было найти через поисковые системы.
5. Может ли мой сайт быть проиндексирован поисковыми системами?
Лучший способ ответить на этот вопрос - создать учетную запись на ContentKing, чтобы оценить, насколько хорошо ваш сайт может быть проиндексирован поисковыми системами. Как вы прочитали выше, существует множество способов повлиять на то, как поисковые системы индексируют ваш сайт.
6. Часто ли Google индексирует мой сайт?
Сколько раз Google исследует ваш сайт. Сканеры пересылают все найденное индексаторам, которые индексируют себя на ваших сайтах.
7. Сколько времени понадобится Google, чтобы проиндексировать мой сайт?
Есть несколько ответов на этот вопрос, потому что это зависит от продвижения только что созданного сайта. Содействие этому ускоряет процесс сканирования и индексации. Успешно, небольшой сайт может быть проиндексирован за один час. Кроме того, иногда может потребоваться месяцы, чтобы полностью проиндексировать новый сайт.
Обратите внимание, что ссылки на ваш сайт в поисковых системах не означают, что ваша страница будет отображаться в числе первых результатов. Достижение вершины корзины занимает много, намного больше времени.
Можно запретить поисковым системам индексировать сайт или страницу несколькими способами:
- Тэг meta robots noindex: это очень сильный сигнал, отправляемый поисковым системам, так что они не индексируют страницу. Он не передает сигналы релевантности или авторитета другим страницам.
- Канонический URL: это сигнал умеренной силы, чтобы указать поисковым системам, какую страницу индексировать, а также приписать сигналы релевантности и авторитета.
- Аутентификация HTTP: это только предотвратит исследование и индексацию новых страниц с точки зрения SEO. Тем не менее, в целом это остается лучшим способом предотвратить доступ поисковых систем или нежелательных посетителей к тестовой среде.
- Robots.txt: может использоваться для предотвращения сканирования или индексации новых страниц.
- Управление параметрами. Может использоваться для предотвращения сканирования или индексации URL-адресов, содержащих определенный параметр.
Похожие
Как проиндексировать сайт Google... имательно следит за тем, что происходит в сети и почти на всех сайтах (за исключением тех, которые являются частью Глубокая паутина автоматически попадают в результаты его исследований. Однако в некоторых особых случаях механизм, который «грабит» сеть в поисках новой информации, не выполняет свою работу своевременно. Как скажешь? Это именно то, что произошло с сайтом, который вы создали несколько недель назад? Что Часто задаваемые вопросы SEO
... как правило, увидите, что ваш рейтинг снова улучшится в ближайшие дни. Если рейтинги значительно упали, у вас на сайте может быть проблема, требующая дальнейшего изучения. Во-вторых, Google, возможно, обновил информацию о качестве, что происходит почти ежедневно. Из-за постоянно меняющегося цифрового ландшафта важно, чтобы вы были в курсе последних обновлений Google, чтобы гарантировать, что вы работаете в соответствии с рекомендациями Google. Другая возможность состоит Google Panda
... google-panda.jpg> Google Panda меняет способ, которым мы используем SEO ИМЕЕТ GOOGLE PANDA НАШ МИР? Вы слышали о Google Panda? Это было примерно с февраля 2011 года. С тех пор Google выпустила обновление, которое может повлиять на небольшие веб-сайты. Сам алгоритм фактически начинается с того, что человеческая рабочая сила просматривает сотни сайтов, Карта сайта
... сайта"> SiteMap используется для перечисления всех страниц вашего сайта. Это самый необходимый файл для SEO, потому что поисковым системам нужен этот файл для индексации вашего сайта. Карта сайта состоит из URL-адресов страниц, времени последнего изменения, частоты изменения и приоритета. Все эти элементы необходимы для наилучшей работы поисковых систем. Создание карты сайта - это не временная, а непрерывная работа. Каждый раз, когда вы вносите какие-либо изменения в свой сайт, вам необходимо Google / SEO
Модератор Мои знания SEO несколько устарели, но здесь: - количество «контента» довольно ограничено (достаточно взглянуть на источник страницы), кроме того, ваша страница начинается с подсказки JavaScript; Я не знаю, применимо ли еще это практическое правило, но я полагаю, что хорошей практикой является перемещение как можно большего количества встроенного JavaScript-кода в конец Что такое Колибри Google, а что нет?
... ил на это 15 день рождения о том, что новый алгоритм поиска под названием Hummingbird был запущен примерно месяц назад, многие люди в поисковой индустрии ломали голову, пытаясь точно понять, о чем говорит Google. Очевидно, что это значительно отличалось от прошлых обновлений, учитывая, что «обновление» осталось в значительной степени незамеченным почти всеми самыми популярными SEO-форумами, блогами и лидерами отрасли. Лучшие SEO агентства для позиционирования себя
... как для поисковых систем, так и для разных пользователей. Благодаря SEO-агентствам вы можете помочь поисковым системам узнать, для чего предназначена каждая из ваших страниц, и степень полезности, которую они представляют для пользователей, поскольку все мы хотим знать мнения об услугах или продуктах, которые мы собираемся предоставить. приобретать , и мы хотим ценить опыт других пользователей. Что такое SEO Поисковая оптимизация Как улучшить SEO WordPress сайт
... Google. И многие также делают, как улучшить SEO WordPress сайты неестественно. Если это называется BlackHat Seo. Ну чёрный чёрный точно не хороший Если мы сможем найти хороший способ. Просто найдите белый белый ... он ... Если мы хотим улучшить наш SEO WordPress сайт, мы должны преодолеть несколько критериев, прежде чем перейти к этапам улучшения SEO. Сайт должен работать на нашем собственном хостинге, Установленный WordPress должен обновить последнюю Лучшие инструменты SEO от Google
... сайта , а также при обращении к нему. Есть много вещей, которые вы можете сделать, чтобы улучшить видимость вашего сайта в поисковых системах, таких как Google, Bing и Yahoo. Google имеет несколько инструментов для проверки вашего сайта. Каковы лучшие инструменты Google SEO ? Поисковая система Google: консоль поиска Google Как назначить канонический URL в Wordpress
... мой шаг для установления канонического URL. Первое, что мы делаем, это устанавливаем и активируем некоторые из самых простых плагинов для настройки и наиболее популярные, как Все в одном пакете SEO , Когда мы его активируем, мы переходим к настройке и проверяем, установлен ли флажок «Канонический URL»: Что означает экспериментальный подиум контента Google для SEO?
... ирует новую платформу контента под названием « Сообщения с Google », И это может оказать огромное влияние на поиск бренда, как платного, так и органического. Мы все знаем, что Google боролась с попытками создать собственную социальную сеть; Живая лента Google мертва, и Google Plus, похоже, уже выходит. Эта новая платформа, кажется, имеет некоторые социальные элементы, хотя и сильно отличается от социальной сети.
Комментарии
Поэтому в этом сообщении я отвечу на часто задаваемые вопросы: «Как я могу определить, хорошо ли работает моя SEO-компания?Поэтому в этом сообщении я отвечу на часто задаваемые вопросы: «Как я могу определить, хорошо ли работает моя SEO-компания?» Как измерить успех SEO Если вы не можете измерить это, вы не можете управлять этим. Вы не можете выиграть игру, если не знаете счет. * Вставьте другие клише здесь. * Так как выглядит успех SEO ? Это то, что вы можете измерить? Должен ли я оценить его по количеству ключевых слов, по которым я Но как сделать так, чтобы наш бизнес появлялся на виду в Google, когда кто-то ищет услугу, которую мы также предлагаем, рядом с географической точкой, где ищет парень?
Но как сделать так, чтобы наш бизнес появлялся на виду в Google, когда кто-то ищет услугу, которую мы также предлагаем, рядом с географической точкой, где ищет парень? Что в переводе означает « как сделать Local Seo? ». Ответ находится в «Google My Business», в нашем профиле Google Plus. Как? У вас нет Google Plus? Вы используете только Facebook? Осел! Следуйте за мной, и я объясню, почему у вас должен быть профиль Google Plus со связанной страницей «Мой бизнес», Аз, когда это работает, может быть совпадением, но если это было несколько раз, возможно ли все же быть совпадением?
Но как сделать так, чтобы наш бизнес появлялся на виду в Google, когда кто-то ищет услугу, которую мы также предлагаем, рядом с географической точкой, где ищет парень? Что в переводе означает « как сделать Local Seo? ». Ответ находится в «Google My Business», в нашем профиле Google Plus. Как? У вас нет Google Plus? Вы используете только Facebook? Осел! Следуйте за мной, и я объясню, почему у вас должен быть профиль Google Plus со связанной страницей «Мой бизнес», Еще лучше спросить: если у меня нет ключевых слов в заголовке моего URL, как я могу сделать так, чтобы важный контент моего сайта имел известность в Google?
Еще лучше спросить: если у меня нет ключевых слов в заголовке моего URL, как я могу сделать так, чтобы важный контент моего сайта имел известность в Google? Поверьте, просто не будет ! Еще больше после изменений, внесенных Google в поисковых системах в 2015 году, что дает большую актуальность сайтам с оптимизацией в SEO Настоящая Поэтому крайне важно спросить себя: есть ли у меня то, что они хотят, и могут ли они найти меня?
Поэтому крайне важно спросить себя: есть ли у меня то, что они хотят, и могут ли они найти меня? Местное SEO должно быть первым приоритетом для местных владельцев бизнеса, стремящихся активизировать свои маркетинговые усилия. От этого зависит успех вашего бизнеса. Когда вы не являетесь экспертом в области локальной поисковой оптимизации, вы обнаружите много несоответствий в отрасли. Некоторые люди преуменьшают значимость некоторых аспектов местного SEO и обсуждают другие Что подразумевается под читабельностью текста и сколько он считает (или может ли он считать) для Google как фактор ранжирования?
Что подразумевается под читабельностью текста и сколько он считает (или может ли он считать) для Google как фактор ранжирования? показатели читабельности Идея для этой статьи пришла ко мне, прочитав комментарий Сальваторе Делла Пепа , который Любой может показать вам, что такое SEO, как оно работает и что вы должны учитывать; Однако, как применить это к реальному миру?
Любой может показать вам, что такое SEO, как оно работает и что вы должны учитывать; Однако, как применить это к реальному миру? Для начала любая стратегия SEO требует предварительного анализа сети, чтобы узнать, с чего мы начали. С другой стороны, анализ результатов, отслеживание, выявление областей для улучшения и подготовка отчетов, которые вы можете сравнивать месяц за месяцем, - это важные аспекты, которые вы должны знать, как это сделать, если вы хотите, чтобы ваш бизнес развивался. Какие вопросы задают клиенты, как они говорят о своих проблемах, что они искали, когда нашли вас, какие из ваших продуктов и услуг наиболее прибыльны?
Какие вопросы задают клиенты, как они говорят о своих проблемах, что они искали, когда нашли вас, какие из ваших продуктов и услуг наиболее прибыльны? Это отличное групповое упражнение, которое часто дает дюжину и более отличных идей. Шаг 2. Доски и форум. Практически в каждой отрасли есть несколько активных досок объявлений и форумов, к которым люди обращаются в поисках информации и разговоров. Удивительно, что вы можете найти в этих чатах. Люди часто говорят Каждый раз, когда вы замечаете, что сайт ссылается на одного из ваших конкурентов, спросите себя: «Как они заработали эту ссылку?
Каждый раз, когда вы замечаете, что сайт ссылается на одного из ваших конкурентов, спросите себя: «Как они заработали эту ссылку?» И выясните, как вы можете получить ссылку и на свой сайт. В некоторых случаях вы можете просто создать профиль на сайте и отправить свою ссылку. В других случаях ваш конкурент платит сайту за размещение или предоставляет контент для аудитории сайта, который содержит ссылку. Связь с бизнесом / партнерами: вы можете получить обратные Существует ли карта сайта и соответствует ли карта сайта URL, фактически проиндексированным Google?
Существует ли карта сайта и соответствует ли карта сайта URL, фактически проиндексированным Google? Правильно ли установлена консоль поиска Google? Первоначально был сделан вывод, что сайт должен предоставить Google хорошую основу с точки зрения содержания. С точки зрения SEO, сам по себе сайт был неплохим: метаданные обычно вводились аккуратно. Кроме того, мы всегда находим вещи, и у нас был хороший список рекомендаций после анализа. Однако мы обнаружили, Поисковые системы помогают вам привлечь ваше внимание, но что плохого в том, что как можно больше людей сразу узнают об этом?
Поисковые системы помогают вам привлечь ваше внимание, но что плохого в том, что как можно больше людей сразу узнают об этом? Посетителям все равно, где находится информация, если они находят то, что ищут. И для вас, как для источника этой информации, самое главное, чтобы как можно больше читателей делали то, что вы от них хотите, например: связывались с вами, посещали ваш сайт, следили за вами в Twitter, LinkedIn и т. Д. Независимо от того, поступают ли эти запросы через Google или «дублирующий»
Как работает индексирование?
1. Часто ли Google ищет мой сайт?
2. Могу ли я замедлить сканеры, когда они исследуют мой сайт?
4. Что означает индексация сайта?
5. Может ли мой сайт быть проиндексирован поисковыми системами?
6. Часто ли Google индексирует мой сайт?
7. Сколько времени понадобится Google, чтобы проиндексировать мой сайт?
Есть много способов пойти, так какой метод применять, когда?
На данный момент, как вы можете повлиять на этот процесс и улучшить SEO?
Как работает сканирование?